- Bu hafta Ordered Data Structures dersinin ikinci hafta odevleri uzerinde calisarak basladim haftaya. Bolumun sonunda basit bir ‘challange’ vardi: Verilen bir Tree’de kac tane Node oldugunu vulan bir fonksiyon yazmak uzerine. Veri yapisini ve ilgili fonksiyon asagida:
#include <iostream>
class Node {
public:
Node *left, *right;
Node() { left = right = nullptr; }
~Node() {
delete left;
left = nullptr;
delete right;
right = nullptr;
}
};
int count(Node *n) {
int counter = 0;
if(n != nullptr){
counter++;
counter += count(n->left);
counter += count(n->right);
}
return counter;
}
int main(){
// Define a root node n
Node *n = new Node();
// Add 6 new nodes to the root
n->left = new Node();
n->right = new Node();
n->left->right = new Node();
n->left->left = new Node();
n->right->left = new Node();
n->right->left->right = new Node;
// Print number of nodes in the tree ( = 6)
std::cout << "Number of nodes in the tree: "
<< count(n) << std::endl;
return 0;
}
Gecen haftalarda kafa yordugum Linked List veri yapisi uzerine, Real Python‘da isan Nayinda yazilmis, yine harika bir sekilde yazilmis bir tutorial buldum.
- Python’daki
collectionsmodulundekideque, “doubly linked list” olarak implement edilmis efficient bir yapi. Bu yapiya, onden ve arkadan O(1) zamanda ekleme/cikarma yapipstackvequeuegibi veri yapilari olusturulabiliyor.
from collections import deque >>> llist = deque("abcde") >>> llist deque(['a', 'b', 'c', 'd', 'e']) >>> llist.append("f") >>> llist deque(['a', 'b', 'c', 'd', 'e', 'f']) >>> llist.pop() 'f' >>> llist deque(['a', 'b', 'c', 'd', 'e']) >>> llist.appendleft("z") >>> llist deque(['z', 'a', 'b', 'c', 'd', 'e']) >>> llist.popleft() 'z' >>> llist deque(['a', 'b', 'c', 'd', 'e'])- Kendi “linked-list” class’ini implement etmek istersen de (insert ve remove metodlari disindaki temel yapi):
class Node(): def __init__(self, data): self.data = data self.next = None def __repr__(self): return self.data class LinkedList(): def __init__(self): self.head = None def __repr__(self): node = self.head nodes = [] while(node is not None): nodes.append(node.data) node = node.next nodes.append(None) return "->".join(nodes)Linked-list’lerin kullanildigi alanlardan biri de graflarin temsili. Verilen bir graftaki komsuluk (adjacency) iliskisini tanimlamak icin de her bir dugumun (node), komsulari bir linked-list olarak ifade edilebiliyormus.
Bunlarin yaninda, karsilastirma amacli olarak Python’daki
listyapilarindan bahsetiklerinde, bu yapilarin Python’da nasil implement edildiklerini anlatan guzel bir baglanti veriyor yazida: How are lists implemented in CPython Bununla iliskili de detayli bir blog yazisi: Python List Implementation Son olarak da bu yazidan ‘zipladigim’ su guzel gorsellestirilmis yazi Python IllustratedYazidan gordugum fakat incelemeye firsat bulamadigim enterasan bir veri yapisi: Fibonacci Heap
- Python’daki
Bugun LeetCode’da nispeten kolay bir problem vardi: verilen bir sayinin 2’nin bir ussu olup olmadigini kontrol eden bir program. Sayinin ikilik sistemdeki gosteriminden yola cikarak, biraz dolayli ve cirkin bir cozum yapmis olsam da, cozumum asagida:
def isPowerOfTwo(self, n: int) -> bool:
#convert to binary and make the digits a list
binary = list("{0:b}".format(n))
#check for 0 and 1
if(len(binary) == 1):
check = (binary[0] == '1')
#check for other 2's powers
#true if the first digit is 1 and the remaining digits are all zeros
else:
check = (binary[0] == '1' and set(binary[1:]) == set(['0']))
return check
Youtube’dan cozumlerini takip ettim arkadas yine birkac satirlik en guzel cozumu bulmayi basarmis: video
Cozumunde ikilik sistemde bir sayi ile o sayinin “2’s complement”ini bir biriyle “bitwise AND” islemine soktugumuzda yine ayni sayiyi verdigi gercegini kullanmis. Ikilik sistemde bir sayinin 2’s complementi o sayinin negatifi oldugundan, en bastaki sifir kontrolunden sonra dogrudan return n & -n == n ile olayi bitiriyor… Ya da daha guzeli, dogrudan sayinin 2’lik tabanda logaritmasini alip cikan sayinin tam sayi olup olmadigini kontrol etmek de guzel bir cozum: return math.log2(n)%1==0 if n>0 else False
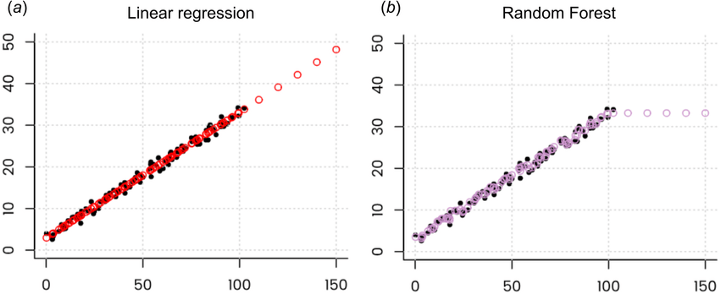
Twitter’dan rastgele gordugum bir yazida Linear Regression ve Random Forest Regressor (RFR)‘i karsilastirip, regression tipi problemlerde RFR kullanimi inceleniyordu. Random Forest’larin regression problemleri icin kullanimi bana hep enteresan gelmistir; zira en en nihayetinde RF’in verdigi sonuc, gunun sonunda bir oylama veya ortalama alma sonucu. Bu durumun en nihayetinde bir extrapolation problemine neden olabilecegini sezmis olsam da hic acik olarak dusunmemistim. Yazida, asagidaki gorselle bunu cok guzel bir sekilde ozetliyor:
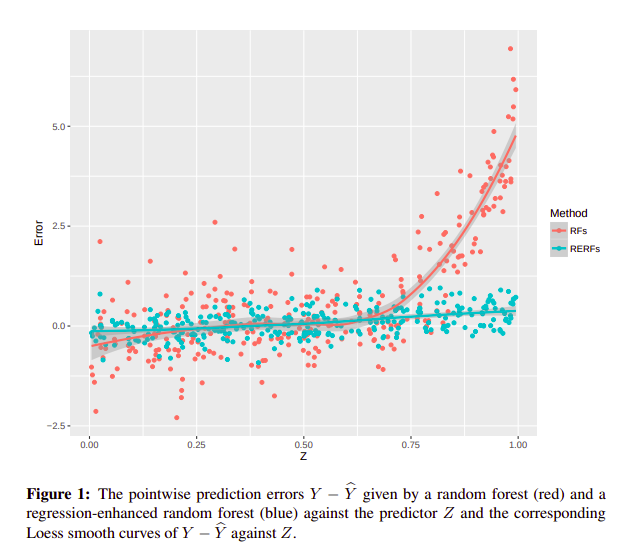
Solda Linear Regression, training set’de gorulmeyen degerler icin extrapolate edebilirken, sagda RFR bunu yapamiyor. Kaynak: Hengl, Tomislav et. al, 2018 - Bu problemi asmak icin modifiye edilmis bir RFR onerilmis: Regression-Enhanced Random Forests(RERFs). Bu yontemle, RFR oncesi veriye
Lassoile bir regression yapilip, cikan residual‘lara Random Forest uygulaniyor. Boylece dogrudan RFR uygulamanin getirdigi extrapolation probleminden kurtulunuyor, training set disinda kalan degerler icin de tahminler yapilabiliyor.
Kaynak: Haozhe Zhang et. al 2019 - Alternatif bir cozum olarak da bu iki regressor’u ust uste stack etmek onerilmis. Kaggle’da bircok cozumde bu tip yaklasimlar gormustum fakat cok dikkatlice incelememisti. Scikit-learn’un resmi dokumatasyonunda guzel bir ornek analiz verilmis, aklimin kenarinda olsun.
- Bu problemi asmak icin modifiye edilmis bir RFR onerilmis: Regression-Enhanced Random Forests(RERFs). Bu yontemle, RFR oncesi veriye
PyCon 2020’de verilen harika konusmalardan birini daha izledim bugun: Beautiful Python Refactoring Konusmaci, Conor, Hoekstra, 60 satirlik bir kodu alip, cesitli sadelestirmeler ve Python yapilari kullanarak, refactor ediyor ve bunu adim adim anlatiyor. Python’un kendine has ozellikleriyle hasir nesir oldukca bu tip duzenlemeleri onceden direkt gormeye basladigimi fark ettim. Tum konusmanin bence en guzel ozeti, bu tip refactoring adimlari icin, kullandiginiz dilin ozelliklerini, kullanabileceginiz etkili algoritmayi ve hatta varsa bu yontemi uygulayan kutuphane bilesenlerini tanimak cok onemli.

Python’un bu tip “cool” ozellikleri icin konusmacinin da onerdigi, DEV.to’daki yazi epey guzel bu arada: 8 Coolest Python Programming Language Features
Konusmacinin, sunum stilinin basarisindan yola cikarak Youtube sayfasindaki diger islere baktigimda epey etkileyici bir liste oldugunu gordum. Hatta yakin zamanda Structure and Interpretation of Computer Programs kitabini chapter-chapter islemeye baslamis. Iste buna gunun kesfi diyebilirim!
Programlama temelleri ve Istatistik’in uzerine bir de Lineer Cebir temelleri koymaya niyetliydim; bunun icin tipik lisans dersinin otesinde bir seyler ararken yeni kesfettim ki yillar once lineer cebiri kendisinden buyuk bir keyifle ogrendigim MIT’den Gilbert Strang sahalara donmus ve temel dersin ustune, biraz daha modern konulara egilen yeni bir lineer cebir dersi kaydetmis: Matrix Methods in Data Analysis, Signal Processing, and Machine Learning Ilk dersten daha, temel matris carpimindan, ic carpima kadar bircok konuya yepyeni bir bakis acisi saglayarak basladi ders. Bundan daha iyisi olamazdi sanirim. Ilk dersten aldigim birkac not.
Ax = b gibi bir matris carpiminda (A matris ve x bir vektor), cikan b vektoru, A’nun column space‘inde yer aliyor.
A matrisini A = CxR seklinde, C matrisi A’nin birbirinden bagimsiz kolonlari, R’de A’nin birbirinden bagimsiz satirlari olacak sekilde decompose edebiliyoruz. Buradan yola cikarak da A’nin column rank degerinin row rank degerine esit oldugunu gorebiliyoruz.
AxB matris-matris carpimini, A’nin satirlari carpi B’nin kolonlari olarak gormek yerine, Ax = b carpiminda oldugu gibi A’nin kolonlari ve B’nin satirlarinin carpiminin kombinasyonu olarak (sum of outer products) da dusunebiliriz. Yani matris-matris carpimi, matris-vektor carpiminin bir nevi genellestirilmis hali… Iste bu benim icin yepyeni bir perpektif…