Numerik hesaplama yaparken ya da veri analizi sirasinda
pandaskullanirken kacinilmaz olarak arka taraftanumpy.ndarrayyapilari kullaniyoruz. Python’daki tipiklistyapilarindan, icindeki verinin tutulma seklinden, hafizada kapladigi yere, uzerinde cesitli numerik hesaplamalar yapmaya kadar bircok avantaj barindiran bu veri yapisini en iyi sekilde ogrenmek, bilimsel hesaplama & veri analizi yapan herkesin boynunun borcu sanirim. Bu amacla ben de bildiklerimi tazelemek ve biraz daha detaylara inmek icin bir tutorial bakarken gecen yil SciPy 2019 konferansinda verilen “Introduction to Numerical Computing With NumPy” egitimini izledim; sunumdan kayda deger birkac not asagida:numpy.ndarray‘ler tipki liste yapilari gibi indekslenip, verilen bir indeksteki deger dogrudan degistirilebiliyor. Fakat bunu yaparken array’in icindeki veri tipinin tutarliligina dikkat etmek gerekiyor.
>>> a = np.array([1, 2, 3, 4]) >>> a[0] = 10 >>> a array([10, 2, 3, 4]) >>> a.dtype dtype('int32') >>> a[0] = 10.6 >>> a array([10, 1, 2, 3])Birden fazla boyutlu array’leri indekslerken “[1][3]” yerine tek parantez ile “[1,3]” kullanilabiliyor. En az iki parantez kazanc demek bu…
Index slicing sirasinda, soldan saga artan indexin yaninda, en sonda -1’den baslayip sola dogru azalan indexe gore de dusunup islem yapmak bazen hayati kolaylastirabiliyor.
# -5 -4 -3 -2 -1 # indices: 0 1 2 3 4 >>> a = np.array([10,11,12,13,14]) # [10, 11, 12, 13, 14] >>> a[1:3] array([11, 12]) # negative indices work also >>> a[1:-2] array([11, 12])- Slicing ile yeni bir veri olusturmuyor, bir referans olusturuyorsun. Sonrasinda olusturdugun veri uzerinde degisiklik yaparsan orijinal veriyi de degistirmis oluyorsun. Bu epey tehlikeli bir sey! Bunun olmamasi icin
.copy()metodu kullanarak yeni veri olusturmak gerek.
>>> a = np.array([0, 1, 2, 3, 4]) # slicing the last two elements returns the data there >>> a[-2:] array([3, 4]) # we can insert an iterable of length two >>> a[-2:] = [-1, -2] >>> a array([ 0, 1, 2, -1, -2]) # or a scalar value >>> a[-2:] = 99 >>> a array([ 0, 1, 2, 99, 99])- “Fancy indexing” adinda epey kullanisli bir yontem mevcut. Slicing yerine, istenen verinin indexlerini bir liste olarak vererek, ilgili veriye ulasmak mumkun. Ustelik bu liste, bir maske gorevi gorebilen bir Boolean Mask‘de olabilir.
>>> a = np.arange(0, 80, 10) # fancy indexing >>> indices = [1, 2, -3] >>> y = a[indices] >>> print(y) [10 20 50] # manual creation of masks >>> mask = np.array( ... [0, 1, 1, 0, 0, 1, 0, 0], ... dtype=bool) # fancy indexing >>> y = a[mask] >>> print(y) array([99, 99, 99])numpy.ndarray‘in kullandigi veri yapisi ve bunun hafizada saklanma bicimi, bu veri yapisinin bu kadar etkili olmasini acikliyor. Veri ile birlikte, array’in sekli (shape), boyutu (dim) ve en onemlisistridebilgisi tutuluyor.stridebilgisi, array’in kolonlari arasinda ve yan yana elemanlari arasinda gecis yaparken hafizda kac byte atlanmasi gerektigi bilgisini barindiriyor.numpy.ndarray‘lerin en guzel ozelliklerinden biri, ornegin bir matrisin transpozunu aldiginizda yada bir slicing yaptiginizda arka tarafta yeni bir veri olusturmak yerine, shape, dim ve stride bilgilerini degistirip hafizada yine ayni bolgeye isaret eden bir obje donuyor olmasi. Boylece (cogu durumda) yeni veri olusturmak gibi “pahali” bir islem gerceklestirmeden isleme devam edilebiliyor. Bahsi gecen obje yapisi asagidaki slaytta mevcut:
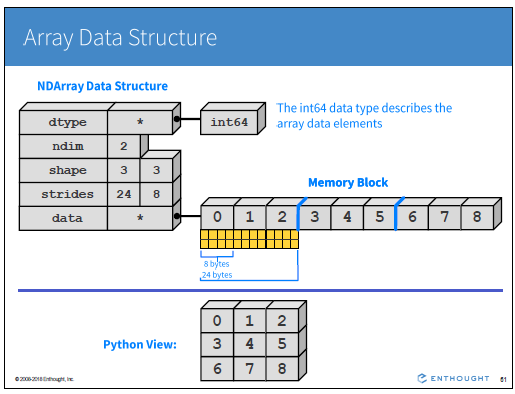
Kaynak: SciPy 2019 Tutorial | Alex Chabot-Leclerc Tutorial materyallerine ilgili Github sayfasindan ulasilabilir.
numpykonusunda biraz daha devam edip, daha da derinlere dalmaya niyetliler icin gecen Brandon Rohrer’in paylastigi Numpy Resources sayfasindaki basliklari tavsiye ederim.Bir sonraki hedef, vites yukseltip Scipy 2019 Tokyo’daki “Advanced Numpy” konusmasi…