Haftasonu haftadan kalan isleri tamamlayip,muhtelif konularda sagdan soldan gordugum, okudugum, izledigim seylere zaman ayirdigim bir gun gecirdim. Geriye baktigimda gunden epey sey kaldigini goruyorum.
Columbia Unv.‘den A. Muller’in Applied Machine Learning dersine devam. Bugunku ders Pre-processing uzerine. Veriyi modele gondermeden yapilmasi gereken donusumler ve bunlarin dogru sekilde yapilmasinin ne kadar onemli oldugunu;
scikit-learnile bunlari yapmanin aslinda ne kadar efektif oldugunu gosteren harika bir dersti. Kisa kisa:Oncelikle veriyi “scale” etmek… Ozellikle veri noktalari arasinda “uzaklik” bilgisinin kullanildigi bir model kullaniyorsak (orn. k-Nearest Neighbor, SVM vs…) veriyi, train oncesi scale etmek cok onemli. Iki tip yontem siklikla kullaniliyor:
StandardScalerveMinMaxScaler.Scale ederken, veri setindeki “outlier”larin ortalama/standart sapma hesabina katilmasini engellemek istiyorsak en guvenlisi
RobustScalerkullanmak. Bu scaler, verinin belirli bir quantile icine dusenlere bakarak ortalama ve standart sapma degerleri hesapliyor. Boylece daha “robust” istatistik degerleri kullaniyor.Bir baska onemli konu, scale ederken, sadece training verisine fit edip, train ve test verisini transform etmek onemli. Aksi durumda test setinden bilgi sizdirmis oluyoruz.
Ayrica icinde bol 0 (sifir) olan “sparse” bir veri seti varsa elimizde, scale ederken ortalama degerini cikarmak, bir suru sifir olmayan yeni degerler uretecek ve bu da epey buyuk yer kaplayacak. Bu durumlarda
MaxAbsScalerkullanmak gerek. Bununla ilgili kolondaki en yuksek deger 1’e scale ediliyor, diger veriler de 1/max_deger ile carpiliyor, sifirlar ayni kaliyor.
Veriyi “preprocess” ederken, olceklerken de karsimiza cikan, test verisinden herhangi bir sekilde bilgi sizdirmama problemi cok kritik. Tipik cross-validation uygulamalari bunu goz ardi edilerek yapiliyor cogu zaman. Ornegin:
# select most informative 5% of features from sklearn.feature_selection import SelectPercentile, f_regression select = SelectPercentile(score_func=f_regression, percentile=5) select.fit(X_train, y) X_selected = select.transform(X_train) print(X_selected.shape) from sklearn.model_selection import cross_val_score from sklearn.linear_model import Ridge np.mean(cross_val_score(Ridge(), X_selected, y))Ustte, ilk basa
SelectPercentileile bir “feature selection” yapiliyor tum veri kullanilarak. Ardindan cross validation uygulaniyor. Fakat burada bir problem var. Her ne kadar ilk donusumu train set uzerinde tanimlamis olsak da, bu adim cross validation icinde yeni olusturulacak train-validation ayriminin icine bilgi sizdirmis oluyor. Cross-validation loop’u icinde olan sey aslinda su:#BAD select.fit(X_train, y) # includes the cv test parts! X_sel = select.transform(X_train) scores = [] for train, test in cv.split(X_train, y): ridge = Ridge().fit(X_sel[train], y[train]) score = ridge.score(X_sel[test], y[test]) scores.append(score)Aslinda yapilmasi gerek olan, preprocessing adimi cross-validation loop icinde her bir ayrim icin ayri ayri yapilip, bu ayrimlardan train olacak olan veri fit edilip, validation olacak olan veriye sadece transform uygulanmali. Boylece validation icindeki bilgi train’e sizmasin. Yani kisacasi olmasi gereken acik olarak su:
# GOOD! scores = [] for train, test in cv.split(X, y): select.fit(X[train], y[train]) X_sel_train = select.transform(X[train]) ridge = Ridge().fit(X_sel_train, y[train]) X_sel_test = select.transform(X[test]) score = ridge.score(X_sel_test, y[test]) scores.append(score)scikit-learn‘de bu tip problemleri onlemek ve tum bu processing adimlarini birbirine bagli adimlar seklinde gerceklestirmek icinpipelineyapilari kullaniliyor. Ornegin ustteki sureci kisaca su sekilde tanimladigimizda hem temiz bir analiz kodu olusturuyoruz hem de ustteki problemi dert etmiyoruz, cunku arka plandascikit-learnbu problemi bizim icin hallediyor.# BEST! pipe = make_pipeline(select, Ridge()) np.mean(cross_val_score(pipe, X, y))Pipeline’lar ile muthis karmasik isleri kolaylikla yapabilmek mumkun. Aradaki tum preprocessing adimlarini ve sonrasindaki model adimlarini tek tek isimlendirip, siraya sokabiliyoruz; sonrasinda bu pipeline‘i
cross-validationhattadaGridCV‘nin icine dogrudan yerlestirebiliyoruz. Boylece farkli modelleri ve farkli parametrelerini, hatta farkli preprocessing adimlari uzerinden grid search yapamabilmek mumkun. Cilgin bir ornek:from sklearn.tree import DecisionTreeRegressor pipe = Pipeline([('scaler', StandardScaler()), ('regressor', Ridge())]) # check out searchgrid for more convenience param_grid = [{'regressor': [DecisionTreeRegressor()], 'regressor__max_depth': [2, 3, 4], 'scaler': ['passthrough']}, {'regressor': [Ridge()], 'regressor__alpha': [0.1, 1], 'scaler': [StandardScaler(), MinMaxScaler(), 'passthrough']} ] grid = GridSearchCV(pipe, param_grid) grid.fit(X_train, y_train) grid.score(X_test, y_test)- Pipeline’lar ilgili guzel bir blog post: Scikit-learn Pipelines: Custom Transformers and Pandas integration
Preprocessing asamasinin bir baska bas agritan konusu kategorik degiskenler. Bunlari bir sekilde numerik degerlere donusturmek gerekiyor.
Bunun icin en ideal yontem
OneHotEncodingkullanmak. Pandas’dapd.get_dummies()fonksiyonu ile dogrudan verilen kategorik degisken icin one-hot-encoded yeni kolonlar olusturmak mumkun. Hatta, sonucta olusturulacak bu kolonlarin toplaminin 1 olacagi bilindiginden, bir serbestlik derecesini atip, yani kolonlardan birini atip yola devam edilebilir.scikit-learn‘de bunu yapanOneHotEncodermodulu mevcut. Hatta, numerik kolonlari orneginStandardScalerile, kategorik degiskenleri deOneHotEncoderile donustur diyebilecegimizColumnTransformerobjeleri tanimlayabiliyoruz. Sonra bunlari pipeline’a ekleyebiliyoruz.categorical = df.dtypes == object preprocess = make_column_transformer( (StandardScaler(), ~categorical), (OneHotEncoder(), categorical)) model = make_pipeline(preprocess, LogisticRegression())Bir dikkat edilmesi gereken konu, icinde cok fazla kategori barindiran degiskenleri one-hot-encode ettigimizde, gunun sonunda elimizde onlarca yeni kolon oluyor ve bu genelde iyi sonuc vermiyor. Bunun yerine ilgili kolonu,
TargetEncoderile, o degiskenin farkli kategorileri icin target degiskenin ortalamalari ile olusturulacak yeni bir degisken etkili olabiliyor. Ornegin bir veri setindeki posta kutusu adresleri, her posta kutusu degeri icin tahmin edilmek istenen degerin ortalamasi ile degistirilebilir. Tabi bu en nihayetinde tahmin etmek istenen degeri, kullanacagimiz degiskenlere sizmasi problemini de cikariyor gibi geliyor bana ama emin degilim.from category_encoders import TargetEncoder pipe_target = make_pipeline(TargetEncoder(cols='zipcode'), Ridge()) scores = cross_val_score(pipe_target, X, target) np.mean(scores)One-hot-encoding’i
pandas‘da nasil yapildiginin tum detaylari su guzel yazida mevcut: One-Hot Encoding a Feature on a Pandas Dataframe: Examples
Dun, Bogazici Fizik’ten bir arkadasla konusurken, yakin zamanda kendi biyofizik calismalari icin ugrastigi bir simulasyonda problem yasadigini ve elde ettigi sonuclari gorsellestirmek icin kullandigi Paraview programinin istedigi sonucu vermedigini soyledi. Ben de “denemeye deger” deyip, kodu gondermesini istedim, oturup biraz ugrastim. Numerik analizde Partial Differential Equations (PDE)‘ler pek deneyimim oldugu bir konu degil; ufak tekfek birkac sey ogrenmek icin guzel firsat benim icin de.
Eldeki problemde, elimizde x,y,t degiskenlerine bagli bir PDE’yi belirli bir grid icerisinde, zamana bagli olarak cozmek istiyoruz ve her zaman araliginda cozum fonksiyonunu gorsellestirmek istiyoruz. Bu tip problemleri Finite Element Method ile cozen oldukca kullanisli ve anladigim kadariyla piyasa standardi bir paket varmis: Fenix Project Altta yatan yontemin ne oldugu ve kutuphanenin nasil kullanildigini basit bir Poisson denklemi‘ni adim adim cozerek gosteren harika bir tutorial da olusturmuslar.
Bu kutuphane ile yaptiginiz cozumleri .pvd dosyasi olarak kaydedip, sonrasinda cozdugunuz grid’i 2 ya da 3 boyutlu render edebileceginiz bir program ile aciyorsunuz. Bu noktada ParaView devreye giriyor. Epey hacimli bir program, bircok kullanisli ozelligi var. Kabaca arayuzunu karistirip, asina oldum. Ben bu programi, dun gelistirmeye basladigim Turbulance modelini gorsellestirmek icin de kullanirim!
Ayrica bu tip grid cozumlerini daha light-weight gorsellestirmek icin baska bir kutuphane de
vtkplotterGithub. CLI’dan ya da Jupyter Notebook’tan kolaylikla cagrilabiliyor. Tipikmatplotlib‘den cok daha fazla ozellik sunuyor.Neyse, sonrasinda fark ettik ki; cozumleri kaydettigimiz dosyalarin tamamini okumuyormusuz meger gorsellestirme yaparken. Bir de Paraview’un son versiyonu (5.8) Fenix dosyalari ile tam uyumludu degil anlasilan. Eksik dosyalari da indirip, 5.7 surumu ile deneyince ta daaamm!
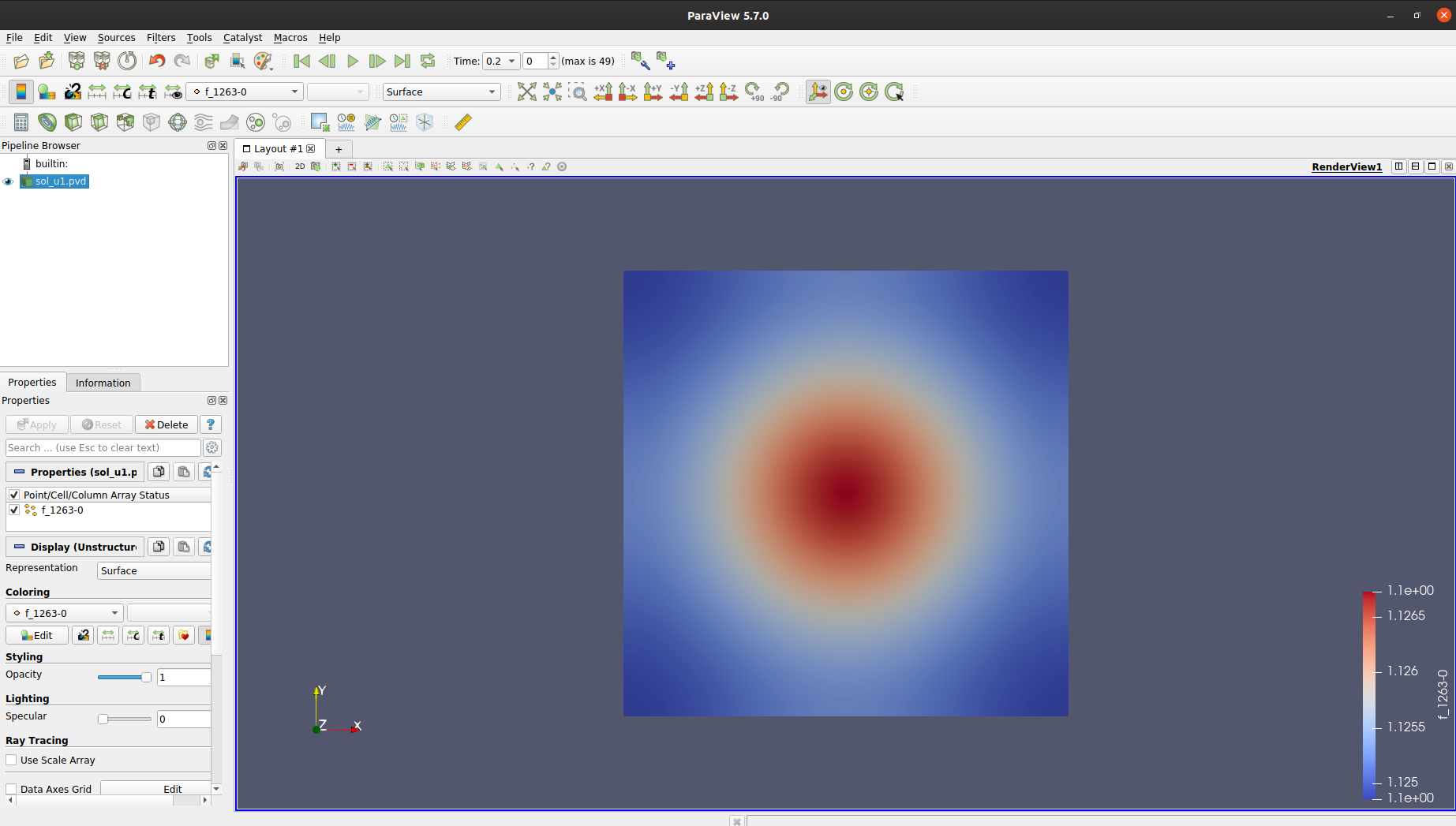
Paraview ile elde ettigim iki boyutlu PDE cozum gorsellestirmesi Bugun Twitter’da rastladigim, yakin zamanda elime gecen High Performance Python kitabinin da yazari Ian Ozsvald,
pandas‘takiSeriesobjeleri ile bu objelerin icindekinumpy.ndarrayobjelerinin farkli veri tipleri icin (int32, float64 vs…) cesitli islemler altinda deneyerek, epey farkli performans gosterdigini gozlemis. Kendi bilgisiyarindaki mimari icin yaptigi testi paylasip, baska kisilerin de analizi tekrarlayip olusturacaklari grafigi, islemci bilgisi ile, olusturdugu repoya gondermesini istemis. Ben de gerekli ortami olusturup, test ettim. Cok benzer sonuclar aldim.numpy.ndarray‘ler, ayni veri tipi icinpandas,Seriesobjelerinden ozellikle float tipler icin 2x, 3x daha hizlilar. Altindaki nedeni epey merak ettim, konuyu merakla takip etmeye devam edecegim.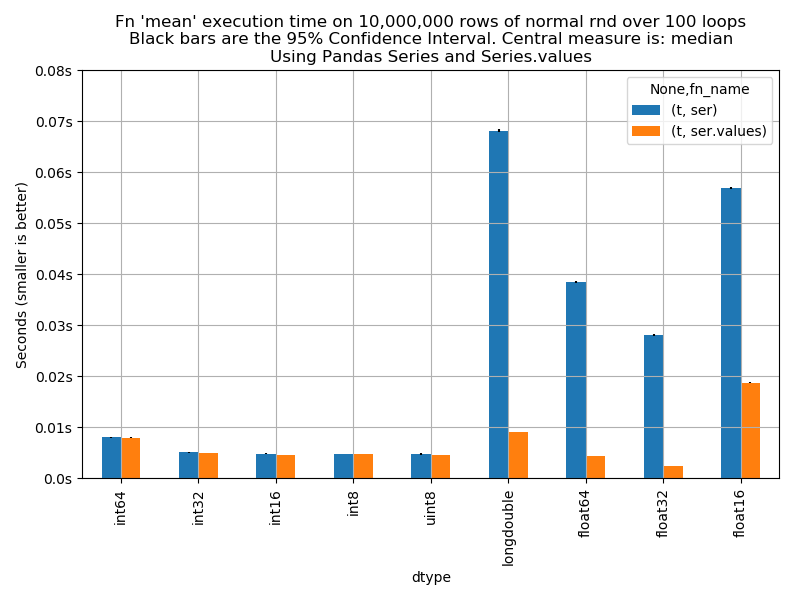
pandas.Series (mavi) ve pure numpy.ndarray (turuncu) peformans karsilastirmasi. Testin yapildigi islemci: 6-Core model: Intel Core i7-9750H bits: 64 type: MT MCP L2 cache: 12.0 MiB Speed: 800 MHz min/max: 800⁄4500 MHz - Bu arada ayni kisinin gecen yil yaptigi su konusma, Python’da performans konusuna cok guzel bir sekilde deginiyor: Tools for High Performance Python - Ian Ozsvald | ODSC Europe 2019
Son olarak da gecen gun izlemeye basladigim PyCon konusmasi Modern Python Developer’s Toolkit‘nin kalan kismini izledim ve her anindan epey faydali seyler ogrendim diyebilirim.
- Oncelikle code style konusunda herkesin kendine gore fikri olsa da belirli standartlari otomatik olarak uygulayan bazi araclar var, mesela
blackgibi. Bir klasor ya da dosya uzerinde dogrudan calistirip otomatik style duzeltmeleri yapabiliyorsunuz. - Bunun otesinde linter ve static code analyzer olarak
Flake8bircok kullanisli ozellik sunuyor. Bircok eklentisi de var. blackveFlake8‘i, projeyi push ettiginizde otomatik calistirmak icin birkac duzenleme yapabiliyorsunuz. Boylece her push ettiginiz degisikligin belirli kod standartlarini sagladigindan emin oluyorsunuz. Nasil yapildigini detaylica anlatan bir makale: refbash‘de direkt kullandigim Python REPL’i yerine Jupyter Notebook’taki promptu dogrudan bash’de kullanabildigim Ipython‘u pek kullanmamistim. Tab completion ve turlu diger ozellikleri nedeniyle bundan sonra REPL’i hayatta kullanmam gibi duruyor.- Testing konusu epey kritik ve basli basina bir konu. Fakat
pytestile, tum bu surec cok kolaylastirilmis gorunuyor. Tabi bu testlerin turlu turlu modifikasyonlari mevcut, en basit uygulamalari icin: ref - Projenin dokumantasyonunu yapmak icin acayip kullanisli bir arac
Sphinx(ref); ayrica projenin dokumantasyonunu ucretsiz olarak host eden Read the Docs sitesi not edilmeye deger. - Tutorial’in son kisminda ornek bir
Flaskprojesi yapip Docker ile deploy ediyor. Bu kismi videoyu bastan sona tekrar izleyip, bir sonraki adimda tamamlayacagim.
- Oncelikle code style konusunda herkesin kendine gore fikri olsa da belirli standartlari otomatik olarak uygulayan bazi araclar var, mesela